Verteilte Systeme
Einzelarbeit vs. Gruppenarbeit
Viele Apskete verteilter Systeme finden sich ähnlich in sozialen Systemen, z.B. Gruppenarbeit. Im Kurs wurden folgende Apskete erarbeitet.
Einzelarbeit
Vorteile
- Scheduling einfacher
- performant / keine Transaktionskosten/Overhead (kein Reden, keine Abstimmung, kein Warten)
- vollständiges Wissen
- Single Point of Truth
- Eigenverantwortung
- sicher (kein Abhören, keine Abhängigkeit)
Gruppenarbeit – Vorteile
- Arbeitsteilung / Entlastung
- Parallelität
- performanter durch Spezialisierung
- Resilienz - Risikoverteilung
- Fehlererkennung
- Skalierbarkeit (ab 2 ist 3,4,5 leicht)
- Robustheit / Fehlertoleranz / Austauschbarkeit
- gemeinsame Nutzung von Ressourcen (Drucker, Papier, Räume)
- einige Aufgaben von Natur aus verteilt, z.B. geographische Trennung
Gruppenarbeit – Nachteile
- erhöhte Komplexität durch Notwendigkeit von Kommunikation
- Fehleranfälligkeit und neue Fehlerklassen
- Übertragungsfehler / Missverständnisse
- Timeout / Halteproblem
- Mehrarbeit wenn unsynchronisiert
- Kompatibilität
- Unsicherheit
- Debugging / Fehlerfindung / unklare Schuldfrage (verschiedene kommunizierende Prozesse sind schwer kontrollierbar und teilweise auch schwer verständlich)
Theoretische Kommunikations-grundlagen
Elemente eines Kommunikationssystems
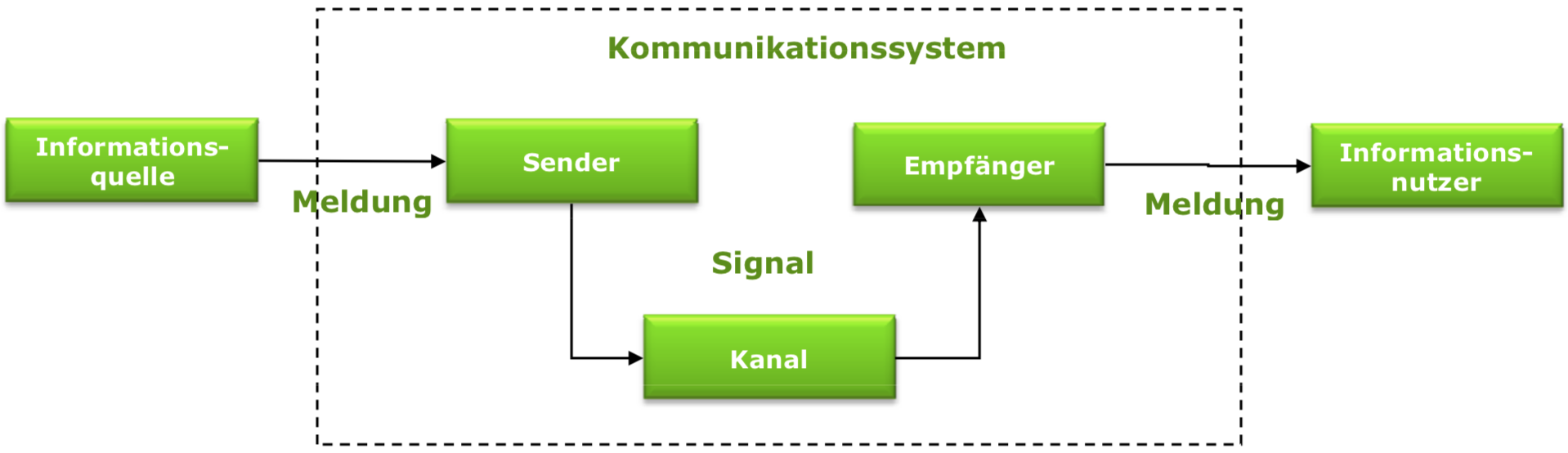
Kommunikationsarten
Richtung
- simplex / unidirektional
- (halbduplex)
- duplex / bidirektional
Übertragung
- Unicast (1 zu 1)
- Multicasting (1 an einige)
- Bradocasting (1 an alle)
Kommunikationsformen
- Textkommunikation
- Datenkommunikation
- Sprachkommunikation (audio)
- Bild- und Videokommunikation
Spezielles Kommunikationsmodell für Computer – Anpassungen
- Meldungen liegen in digitaler Form vor
- Es existiert ein zweiter Kommunikationskanal für Rückmeldungen
- Definition eines Protokolles, das festlegt, was für Meldungen in welcher Reihenfolge ausgetauscht werden
- Rekursive Struktur ein protokoll-erweiterter Kanal kann selbst als (virtueller) Kanal verwendet werden
Verteiltes System
Ein verteiltes System ist ein System,
- in dem sich Hardware und Softwarekomponenten auf vernetzten Computern befinden und
- nur über den Austausch von Nachrichten kommunizieren und ihre Aktionen koordinieren.
Verteilte Anwendung
Eine verteilte Anwendung ist eine Anwendung,
- die ein verteiltes System zur Lösung eines Anwendungsproblems nutzt und
- aus verschiedenen Komponenten besteht, die mit den Komponenten des verteilten Systems sowie mit den Anwendern kommunizieren.
Architekturmodelle
Ein Architekturmodell beschreibt
- die Rollen einer Anwendungskomponente innerhalb der verteilten Anwendung
- die Beziehungen zwischen den Anwendungskomponenten
- Beispiele:
- Client / Server
- Peer-to-Peer
Client / Server
Client-Prozess
- Kurzlebiger Prozess
- Lebt genau für die Dauer der Nutzung durch einen Anwender
- Agiert als Initiator einer IPC
Server-Prozess
- Langlebiger Prozess
- Lebt
unbegrenzt
- Agiert als Diensterbringer einer IPC
Client / Server – Varianten
Mobiler Code
- Servercode wandert auf Anfrage (in Form) zum Client.
- Die Ausführung des Codes erfolgt am Client
- Bekanntes Beispiel dieser Client / Server Variante sind Java Applets.
- Applets als serverseitige Anwendungskomponenten wandern auf Anfrage zum Client.
- Der Browser als Client macht Aufrufe lokal auf dem Applet.
- Bei Bedarf reicht das Applet die Anfragen an den Server weiter.
Client / Server – Varianten
Kooperierende Server
- Ein Verbund von Servern bearbeitet transparent einen Aufruf.
- Verwendung findet dieses Modell beispielsweise im Internet bei Domain-Name-Servern (DNS).
- DNS verwalten Abbildungstabellen von auf IP Adressen.
- Liegt lokal keine Abbildung vor, wird der Aufruf transparent an den DNS-Server weitergeleitet.
Client / Server – Varianten
Replizierte Server
- Es werden Replikate von Serverprozesse zur Verfügung gestellt.
- Beispiele:
- Transparente Replikate in Clustern zur Verbesserung der Performance und zur Ausfallsicherheit.
- öffentliche Replikate zur Lastverteilung (z.B. Mirror Server)
Client / Server – Varianten
Proxy Modell
- Ein Proxy dient als Zwischenspeicher für Aufrufergebnisse vom Server.
- Ziel ist die Verbesserung der Performance
- Beispiel: Proxy zum Zwischenspeichern von Webseiten
Das Tier-Modell
- Tier: Prozessraum in einer verteilten Anwendung
- n-Tier-Architektur legt fest, wie viele unterschiedliche Client- und Server es innerhalb einer verteilten Anwendung gibt.
- Ein Prozessraum kann einem physikalischen Rechner entsprechen.
- Die Verwendung von n-Tier Architekturen ergibt vor allem für Informationssysteme Sinn:
- Verteilung der Software zur Reduktion der
- Interaktive Mensch-Maschine Schnittstelle
- Datenzentriertes Vorgehen
Das Tier-Modell
- Typischen Aufgabenstellungen in einem Informationssystem:
- Präsentation – Schnittstelle zum Anwender
- Anwendungslogik – Bearbeitung der Anfragen
- Datenhaltung – Speicherung der Daten in einer Datenbank
- Im Tier-Modell wird jede dieser Aufgaben der Anwendungskomponente einer einzelnen Tiers zugeordnet.
- Die Art der Zuordnung macht den entscheidenden Unterschied der verschiedenen n-Tier Architekturen.
2-Tier-Architektur
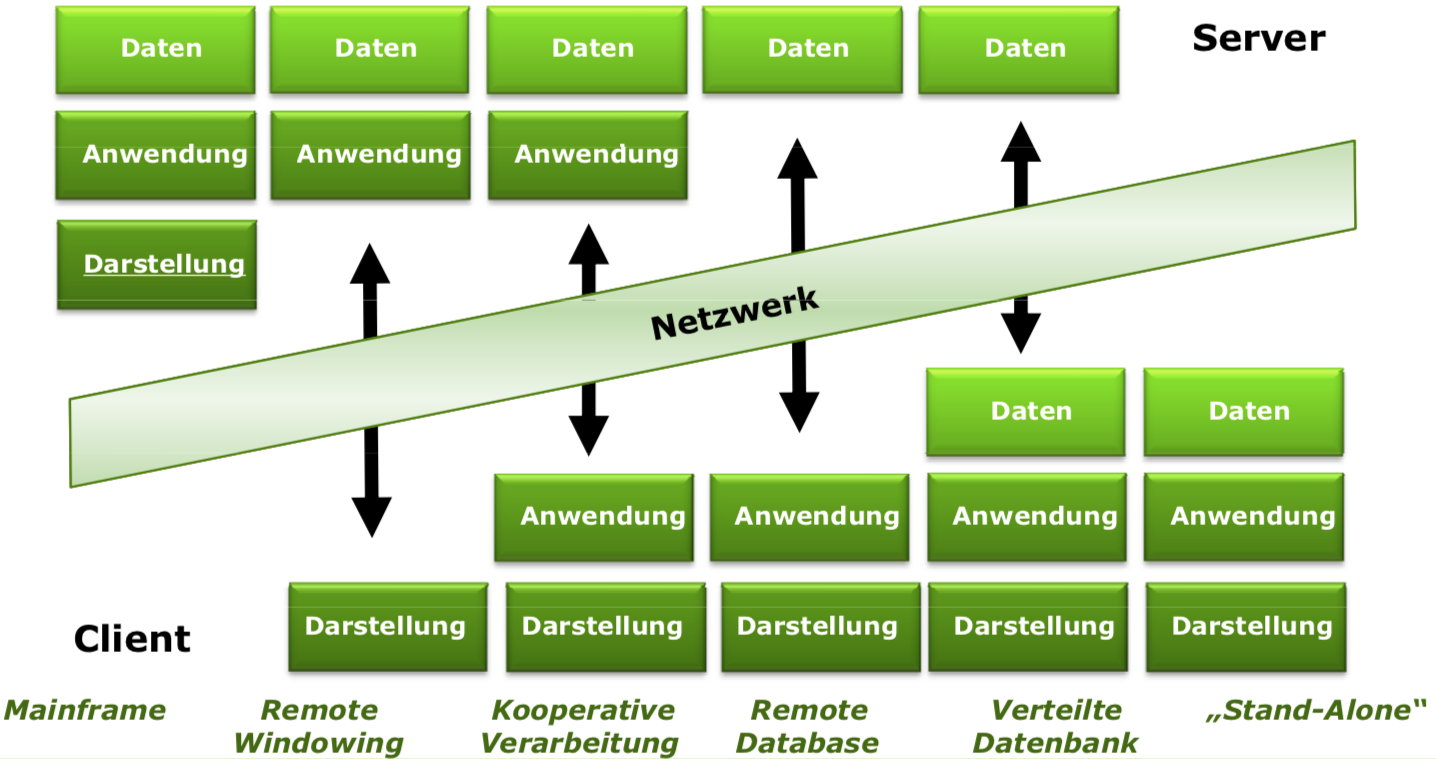
Thin- vs Fat-Client-Architekturen
- sind Verfeinerungsmodelle für die Zuordnung der Anwendungslogik
- Ultra-Thin-Client: Die auf der Client-Tier sich auf reine Anzeige von Dialogen. der Anwendung ist ein Browser.
- Thin-Client: Die auf der Client-Tier sich auf Anzeige von Dialogen und die Aufbereitung der Daten zur Anzeige.
- Fat-Client: Teile der Anwendungslogik liegen zusammen mit der auf der Client-Tier.
3-Tier-Architektur

Peer-to-Peer (P2P)
- Gleichberechtigte Prozesse interagieren miteinander.
- Jeder Prozess kann sowohl als Client- als auch als Serverprozess auftreten.
- Peer Prozess
- Kurzlebiger Prozess
- Lebt für die Dauer der Nutzung durch einen Anwender
- Agiert als Initiator und als Diensterbringer.
- Ziel: von einem zentralen Server.
- Einsatz beispielsweise bei Tauschbörsen.
Vergleich Client/Server und P2P
- Server werden zentral betrieben und administriert
- Ein Client besitzt geringere Ressourcen als der Server
- Die Ressourcen eines Peer sind zu denen anderer Teilnehmer
- P2P – Peers kommunizieren direkt mit anderen Peers und teilen Ressourcen
Eigenschaften P2P
- Skalierbarkeit – Teilen von Ressourcen
- Keine Notwendigkeit zur Einrichtung und Skalierung von Servern
- Jeder Nutzer bring eigene Ressourcen ein
- Zum Beispiel resistent gegen spikes (eine Menge von Nutzern, die alle zur gleichen Zeit eintreffen)
Preiswert
– Keine Infrastruktur erforderlich- Hohe Verfügbarkeit – Inhalt nahezu permanent verfügbar
- Jeder kann seinen eigenen Inhalt einbringen (kostenfrei)
- Selbstgemachter (home-made) Inhalt
- Illegaler Inhalt (P2P = Pirate-to-Pirate)
Technische Kommunikations-grundlagen
ISO OSI-Referenzmodell

Middleware

Middleware
- Ziel: Verbergen der Verteilungsaspekte vor der Anwendung
- Anwendungsaufrufe gehen an Middleware, diese kümmert sich um Weiterreichung über das Netzwerk (meist TCP/IP)
- Wir unterscheiden zwischen:
- Kommunikationsorientierte Middleware
- Anwendungsorientierte Middleware
- Nachrichtenorientierte Middleware
Interprozesskommunikation (IPC)
- Komponenten einer verteilten Anwendung laufen in unterschiedlichen Prozessen
- Kommunikation basiert auf Nachrichtenaustausch in Form von Bitfolgen
- IPC ist ein Mechanismus zum Nachrichtenaustausch zwischen Prozessen
- Kommunikationsmodelle legen das Protokoll für den Ablauf der IPC fest
- Unterscheidung zwischen synchroner und asynchroner Kommunikation
Synchrone Kommunikation
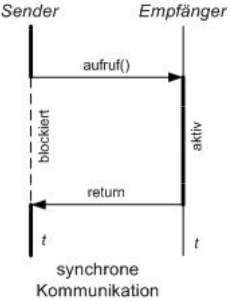
- Sender-Prozess blockiert während Anfrageverarbeitung
- Eigenschaften:
- Enge Kopplung zwischen Sender und Empfänger mit allen Vor- und Nachteilen
- Hohe Abhängigkeit besonders im Fehlerfall
- Voraussetzung:
- sichere und schnelle Netzverbindungen
- empfangender Prozess ist verfügbar
Asynchrone Kommunikation
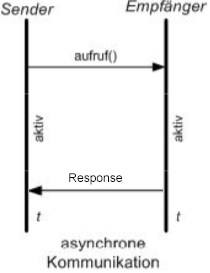
- Sender ist nicht blockiert; Prozess kann nach dem Senden sofort weiterarbeiten
- Antworten sind optional (push / pull)
- Realisierung über Queues:
- komplizierter zu implementieren, dafür effizienter
- lose Koppelung von Prozessen
- geringere Fehlerabhängigkeit
- Empfänger muss nicht empfangsbereit sein
Kommunikationsorientierte Middleware
- Schwerpunkt liegt in der Abstraktion von der Netzwerkprogrammierung
- Dienst als Kommunikationsinfrastruktur
- Konzentriert sich auf reine Kommunikationsaspekte
- Beispiele sind RPC, RMI, Web Service
Anwendungsorientierte Middleware
- Setzt auf der kommunikationsorientierten Middleware auf
- Erweitert diese um Laufzeitumgebung + Dienste + Komponentenmodell
- Beispiele: CORBA, J2EE, .Net
Nachrichtenorientierte Middleware
- englisch
Message Oriented Middleware
(MOM) - arbeitet nicht mit Methoden- oder Funktionsaufrufen, sondern über den Austausch von Nachrichten
- verschiedene Kommunikationsprotokolle:
- Message Passing
- Message Queueing
- Publish & Subscribe
Probleme
- Heterogenität: Hardware, Betriebssysteme, Programmiersprachen, Protokolle, Darstellung von Datentypen, Zeichenkodierungen
- Lösung
- Installationen für verschiedenen Betriebssysteme
- SDKs für verschiedene Programmiersprachen
- Einigung auf einheitliche Datenformate
Datentransformation (Marshalling / Unmarshalling)
- Unter Marshalling versteht man die Transformation von Daten in ein Übertragungsformat.
- Unter Unmarshalling versteht man die Rücktransformation eines Zeichen- oder Bytestroms in Daten einer konkreten Programmiersprache.
Technische Umsetzung
Sockets
- vom Betriebssystem bereitgestelltes Objekt, das als Kommunikationsendpunkt dient
- Ein Socket setzt sich aus IP und Port zusammen., z.B. 141.45.146.226:443 oder 127.0.0.1:3000
- Über diese Programmier-Schnittstelle (API) können Applikationen verteilt über das Netz programmiert werden
Remote Procedure Call (RPC)
- Technik zum Aufruf von Funktionen (mit Parametern) auf anderen Prozessen
- Entkopplung von Client und Server durch Schnittstellendefinition
- Einführung von Stub und Skeleton als Zugriffsschnittstelle auf Client- und Serverseite
- werden aus der Schnittstellenspezifikation generiert
- sind verantwortlich für Marshalling und Unmarshalling
- ermöglichen die Zusicherung von Zugriffs- und Ortstransparenz
- Fehleranfällig
Remote Method Invocation (RMI)
- Java-eigene Art des Remote Procedure Call
- Aufruf von Methoden auf entferntem Objekt
Links und Props
- Viele Folieninhalte von Prof. Hemling